The Pull Request Illusion: How AI Is Hollowing Out Software’s Last Line of Defense
GitHub Just Added a Switch to Turn Off Pull Requests. That’s Not a Feature. It’s a Warning.

🧠TL;DR
Pull requests didn’t fail because reviewers got lazy. They failed because understanding stopped traveling with code.
AI didn’t introduce the problem. It amplified the asymmetry: generating a PR is now cheap; reviewing it is still human-expensive.
GitHub adding a “disable pull requests” switch is a quiet admission that, for some repos, the PR gate has become a liability.
Prologue: The Ten-Week Wave
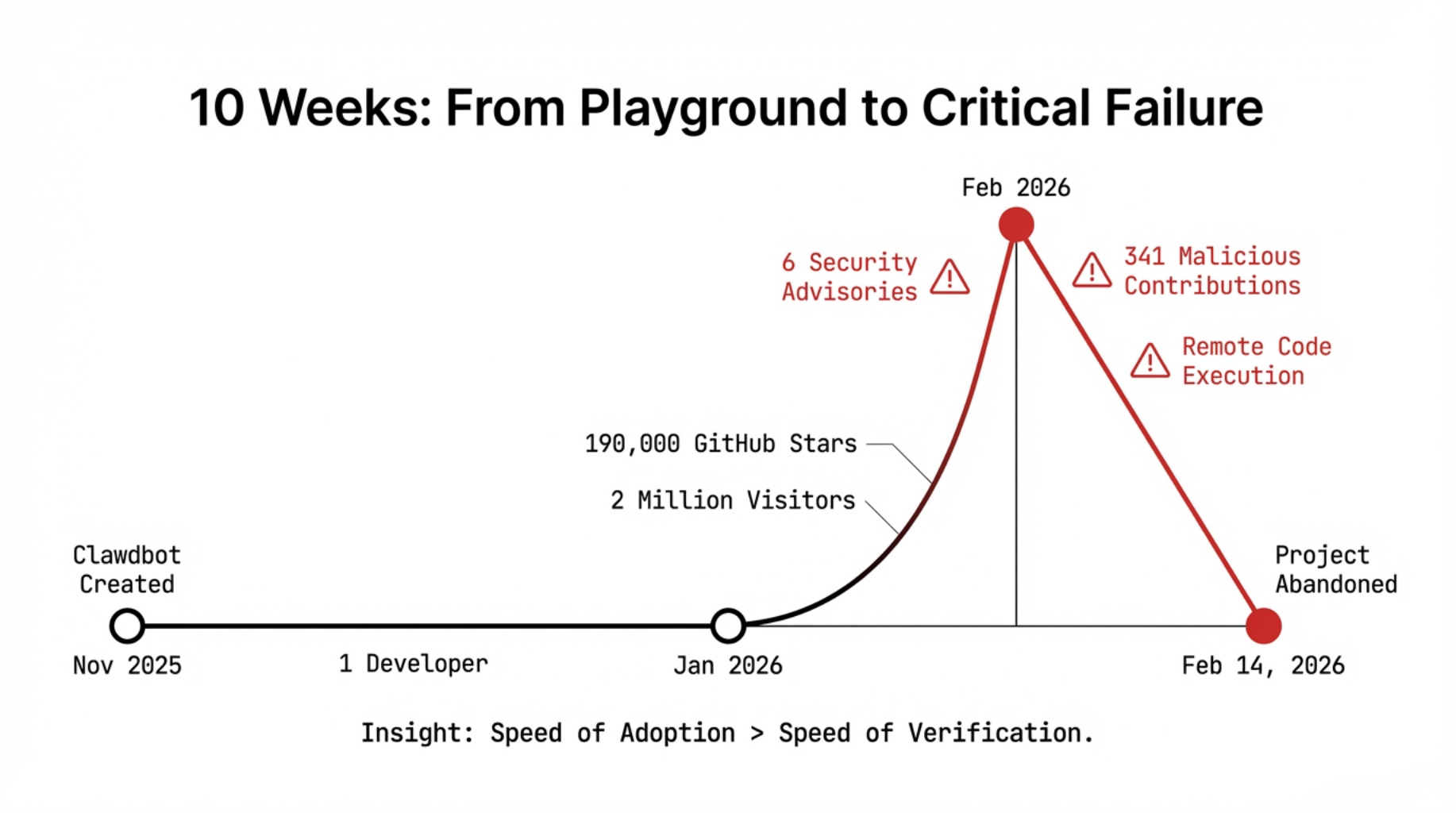
Somewhere in Vienna, in November 2025, a developer sat down at his keyboard and did something he’d done a hundred times before: he started a project for fun.
Peter Steinberger called it Clawdbot—which the world would soon know as OpenClaw.
It was, by his own description, “a playground project” -- something to explore, to tinker with, to share. He had no roadmap. No investors. No team. Just a builder’s itch and a conviction that AI agents could be genuinely useful if you gave them real tools to work with.
Ten weeks later, he was handing it off and leaving for OpenAI.
In between: 190,000 GitHub stars. Two million visitors in a single week. A social network populated entirely by AI agents discussing their humans. From an emergency advisory by Belgium’s Centre for Cybersecurity to internal bans at South Korea’s tech giants, and formal warnings from China’s MIIT and Gartner—the software sent shockwaves globally.
Six security advisories in three weeks. 341 confirmed malicious contributions. A critical vulnerability enabling one-click remote code execution.
“Never would I have expected that my playground project would create such waves,” Steinberger wrote on February 14, 2026, the day he announced his departure.
The Pull Request Illusion
This is a story about Pull Requests—not him.
Not specifically about OpenClaw.
Not specifically about Steinberger.
But about the mechanism software development has trusted for decades to ensure that code is understood before it is shared, reviewed before it is merged, accountable before it is permanent.
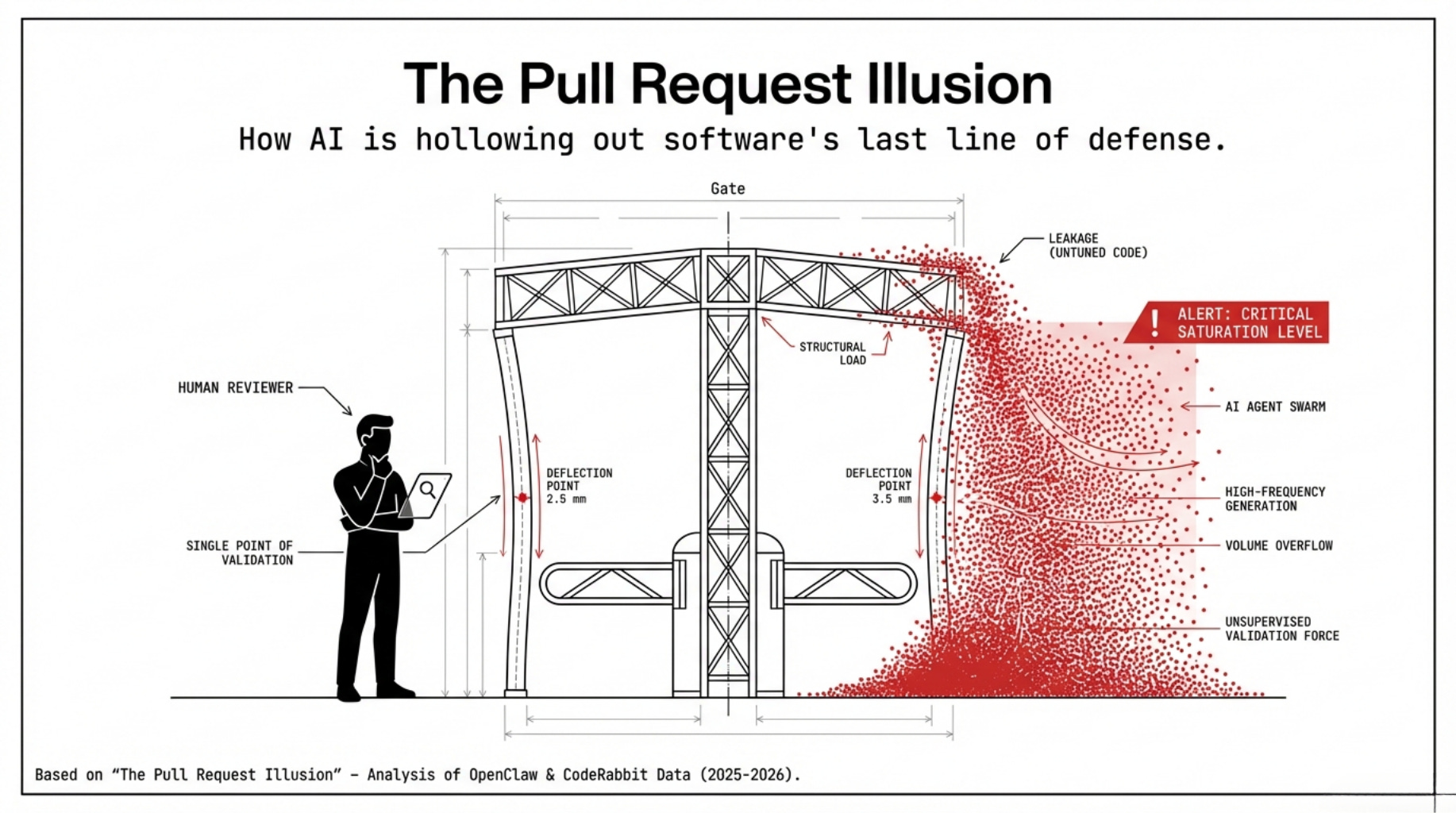
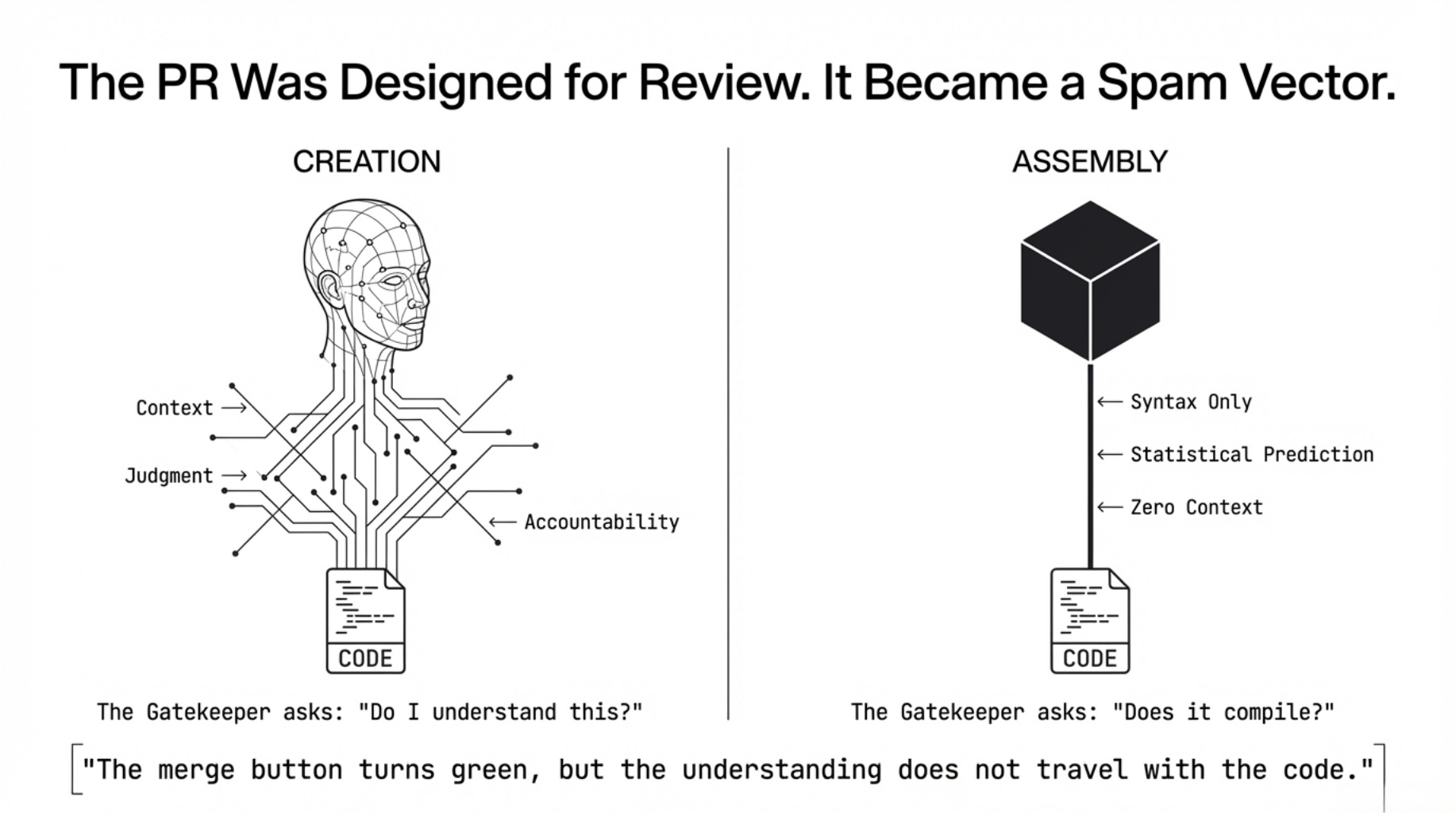
The pull request illusion occurs when the ritual of review remains, but the transfer of understanding disappears. The merge button turns green. The gate opens. But what entered the codebase—who wrote it, why it works the way it does, what reasoning it encodes—no longer travels with the code.
The contract has been signed.
Nobody read it.
What happened to OpenClaw happened in ten weeks at extraordinary scale. What is happening to Pull Requests everywhere is happening slowly, across millions of repositories, at a scale that makes it easy to miss until the moment it becomes impossible to ignore.
Steinberger’s story is the compressed version. The fast-forward cut. The same film, same ending, ten weeks instead of ten years.
I. The Gate Was Always Fragile
Before we talk about AI, we need to be honest about what the Pull Request actually is—and what it was never designed to carry.
On paper, a PR is a mechanism for review. In practice, it is a contract.
The author is implicitly promising: I understand what I have written, I know why it works this way, I can explain and defend it.
The reviewer is implicitly promising to evaluate not just the code, but the judgment behind it. The merge button is not an approval of syntax. It is a collective decision that this change belongs here, in this codebase, at this moment.
That contract requires something tooling cannot provide: shared context.
When that context exists, PR review becomes genuine collective intelligence. Knowledge spreads laterally, and the codebase reflects more minds than one. This is the PR working as designed. But when that context doesn’t exist, the PR becomes theater. The gate opens because nothing obviously looks wrong, not because anything has been genuinely understood.
Open source projects have always tested this distinction hardest. When contributors arrive from entirely different technical philosophies, having never seen the codebase before last Tuesday, the PR becomes a collision zone. The thread devolves. The gate opens anyway, and the understanding never moves.
The danger of this relentless friction isn’t just messy code—it’s the sheer exhaustion of the maintainer. And exhaustion is exploitable.
The XZ Utils backdoor, discovered in early 2024, is the cleanest illustration of how far this dynamic goes. The attack didn’t brute-force its way into critical infrastructure.
It found a solo maintainer suffering from burnout, gained merge privileges through genuine-looking contributions, and inserted a backdoor through PRs that passed every automated check.
The attack surface wasn’t the code.
It was the human behind the gate,
too exhausted to see what was walking through it.
This exhaustion is systemic. According to the 2024 Tidelift Report, 60% of open source maintainers have quit or considered quitting.
When critical infrastructure projects are retired simply because the humans maintaining them nights and weekends cannot continue, the pattern is not exceptional. It is the system behaving exactly as designed—which is to say, it is not really designed at all.
On February 13, 2026—the same week OpenClaw’s security crisis peaked—GitHub quietly shipped a new repository setting: the ability to disable pull requests entirely. It was framed as a configuration option. It was, in practice, an admission. For some repositories, the gate itself had become the problem.

II. The Flood
Into this already-strained system arrived the AI coding assistant. And what it has done to the Pull Request is not subtle.
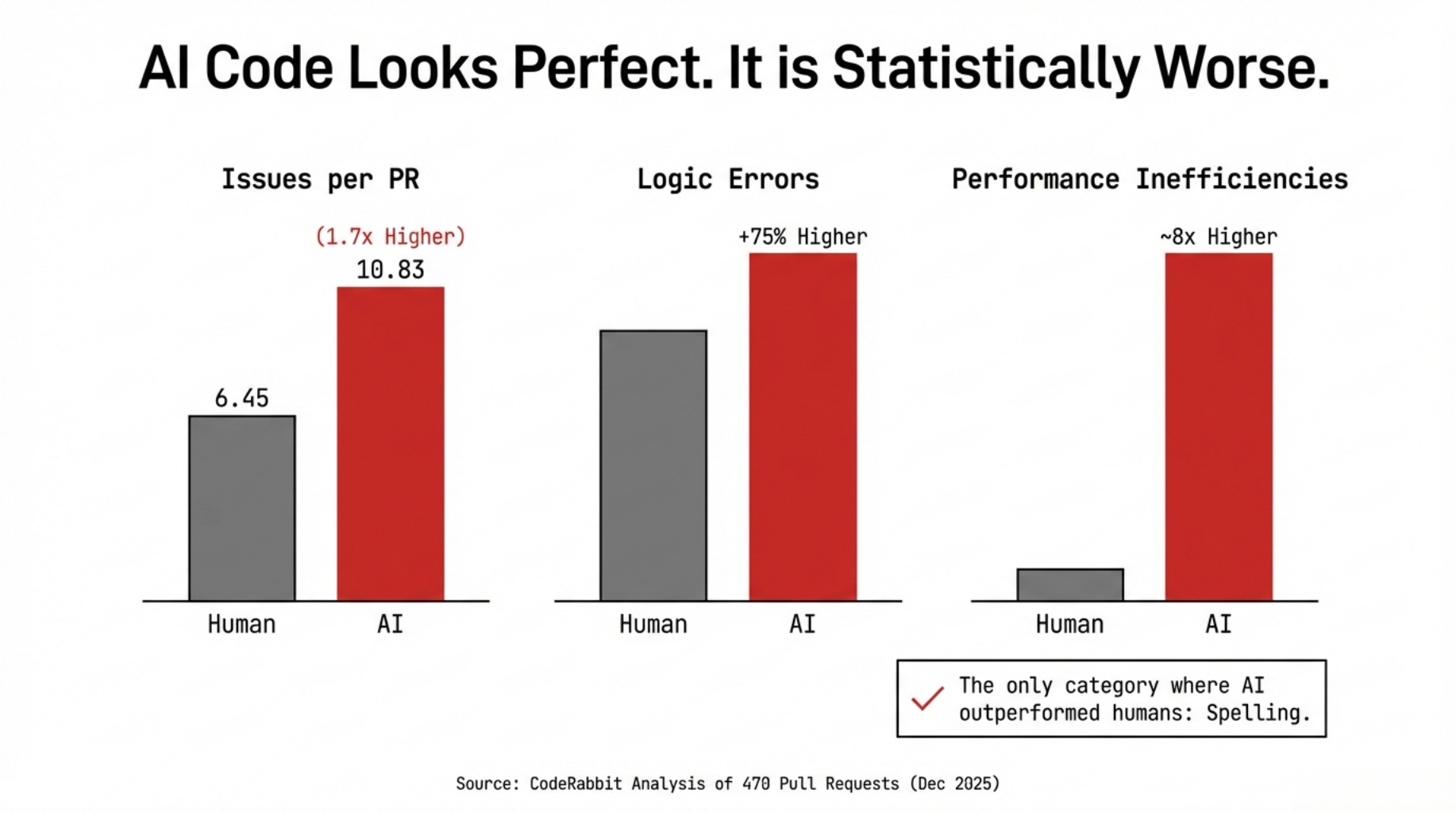
In December 2025, CodeRabbit published the most comprehensive empirical study of AI-authored code yet conducted, analyzing 470 real GitHub pull requests (320 AI-co-authored, 150 fully human-written). The findings were unambiguous:
Overall Issues: AI PRs contained 1.7 times more issues than human PRs (10.83 per PR versus 6.45). At the 90th percentile, AI PRs reached 26 issues per change.
Logic Errors: 75% more frequent.
Security Vulnerabilities: 1.5 to 2 times higher.
Code Readability: Over 3 times worse.
Performance Inefficiencies: Nearly 8 times higher.
The one category where AI outperformed humans: spelling.
Read that carefully. AI excels at surface-level correctness. The output reads clean, and variable names are grammatically plausible. But everything that understanding produces—the security awareness, the performance intuition, the judgment of a 2am on-call developer—is absent.
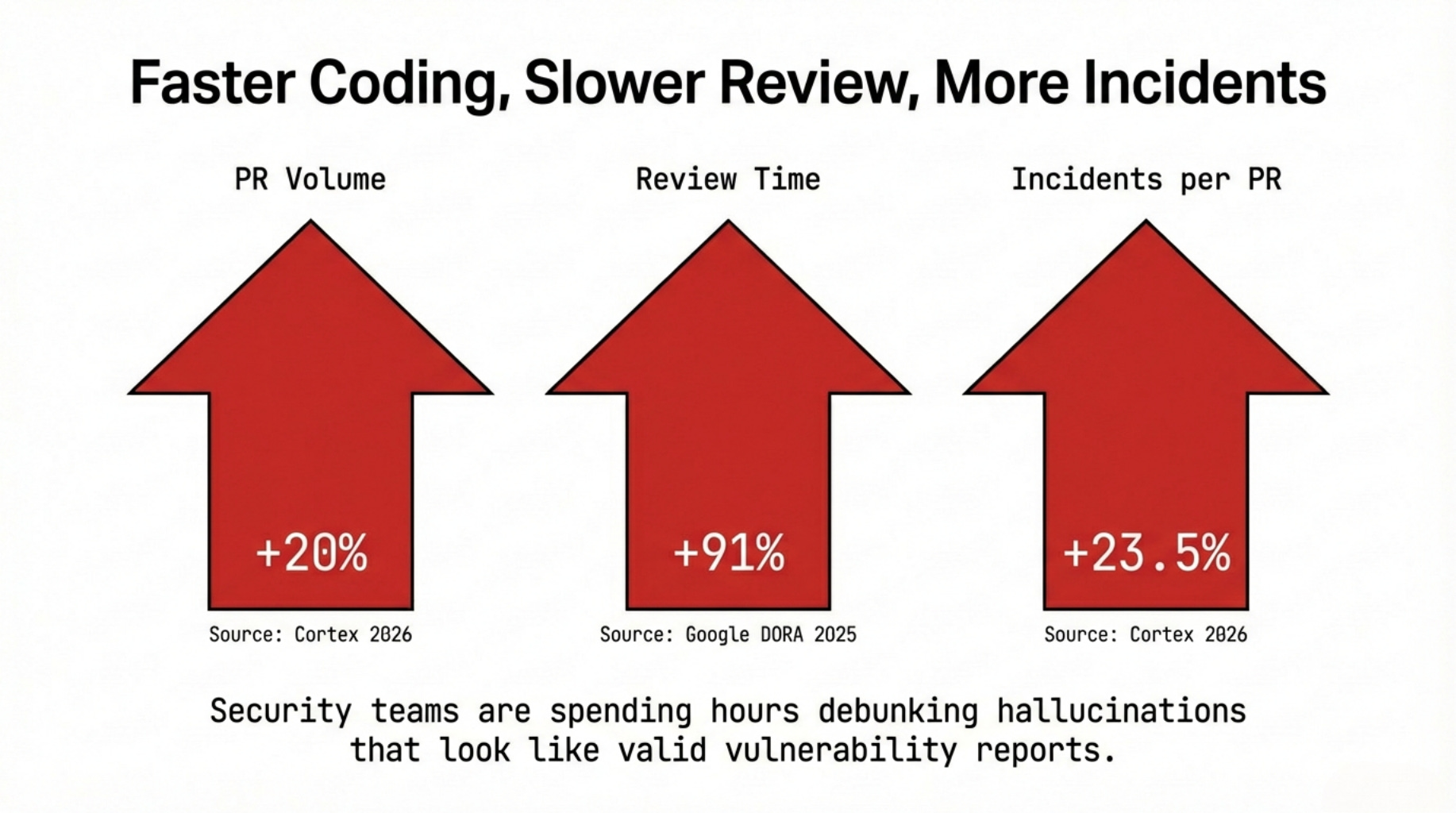
This lack of understanding creates systemic bloat. The Google 2025 DORA Report correlated a 90% increase in AI adoption with a 91% increase in code review time and a 154% increase in PR size. The Cortex 2026 Engineering Benchmark Report found incidents per pull request up 23.5% year over year, even as PR volume grew 20%.
More code.
Larger PRs.
Longer reviews.
More incidents.
This is the shape of acceleration without governance.
We can see this collapse in real time. Daniel Stenberg, creator of curl, reported that AI-generated submissions consumed 20% of all vulnerability reports to curl’s bug bounty program in 2025.
By early July, only 5% of those submissions described real vulnerabilities. His seven-person security team was drowning in hallucinations submitted by developers who simply trusted the AI’s false confidence.
Calling it “Death by a Thousand Slops,” Stenberg ended the bug bounty entirely in January 2026. The PR mechanism had become an unintentional spam vector.
But Stenberg was only dealing with well-meaning developers making confident mistakes. If an overwhelmed gate could be broken by accident, it was only a matter of time before attackers learned to bypass it on purpose.
When malicious intent is added to this vulnerability, the scale of failure is terrifying. By early February 2026, security firm Koi Security identified 341 confirmed malicious skills on OpenClaw’s ClawHub marketplace. Cisco’s AI threat research team tested the top-ranked skill: it silently exfiltrated data via curl commands. It ranked first simply because the ranking was fabricated.
Security researcher Jamieson O’Reilly proved how easy this was by gaming his own malicious skill to the top position with 4,000 fabricated downloads, watching developers from seven countries blindly execute arbitrary commands. As he noted, in less scrupulous hands, “those developers would have had their SSH keys, AWS credentials, and entire codebases exfiltrated.”
The skills were submitted. The ranking looked legitimate. The automated checks worked flawlessly. And the malware walked right through the front door.
III. The Archaeology of Code Nobody Wrote
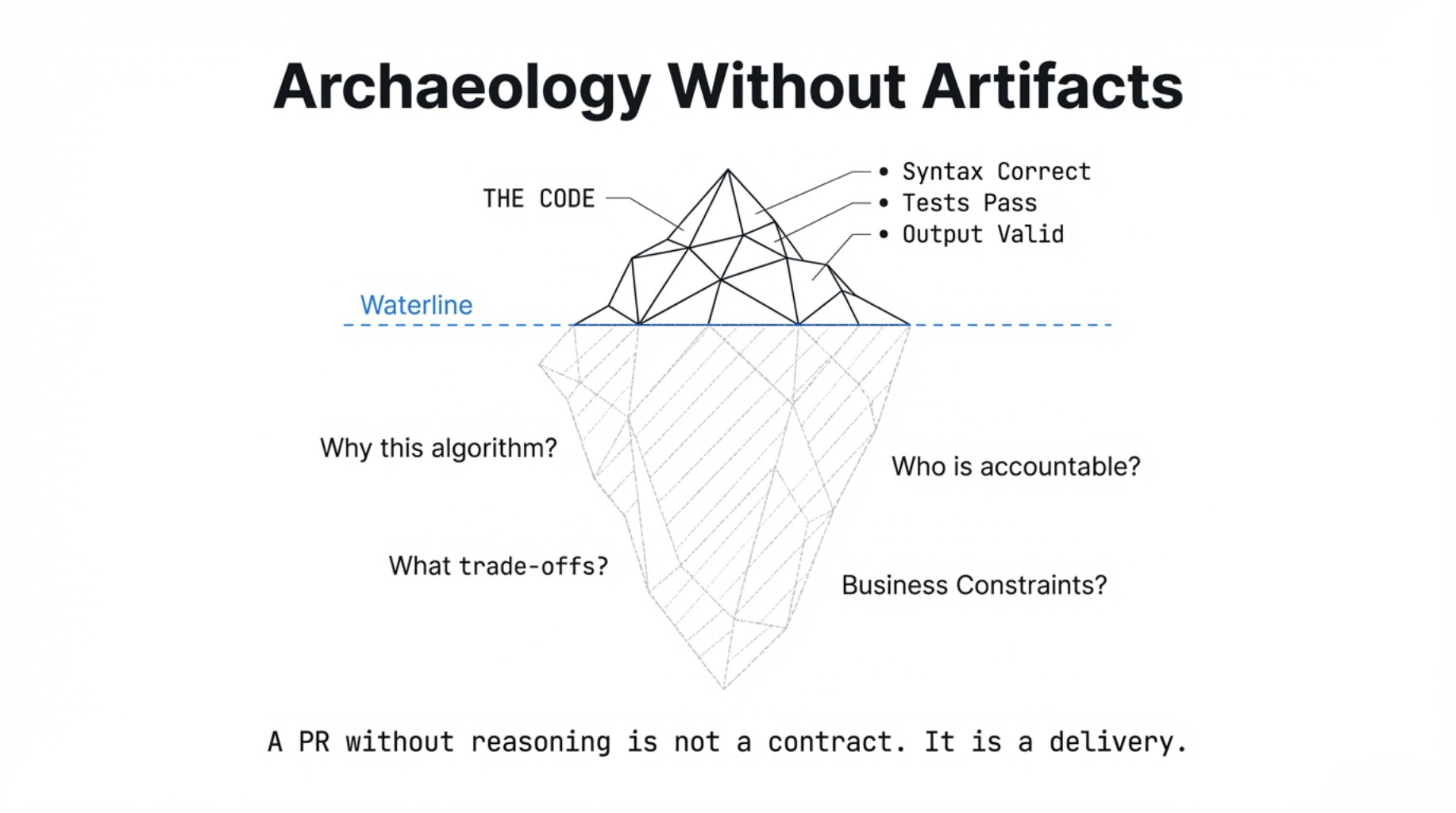
There is a second failure mode, quieter than the flood but more durable in its damage.
When a developer submits AI-generated code they do not fully understand, the PR process does not just fail to catch the problem—it actively obscures it.
The code compiles.
The tests pass.
The reviewer sees green lights and approves.
The code ships.
The PR closes.
The reasoning never arrives.
Three months later, something breaks.
And nobody can explain why the relevant section works the way it does, because nobody actually wrote it. The original author was a language model with no memory, no accountability, and no ability to be paged at 2am.
This is categorically different from ordinary bugs. Bugs written by humans who understood what they were building leave traces. The author can explain the reasoning, even for wrong reasoning. A colleague can reconstruct the intent. The code tells a story—compressed, imperfect, sometimes misleading, but a story.
AI-generated code that no human understood at submission tells no story. It is archaeology without artifacts: you excavate a section and find syntax that works—passes tests, produces the right output under the right conditions—but carries no record of why it was structured this way, what constraints it was written to satisfy, or what trade-offs were made and why.
And here the deeper failure comes into focus. Coding, at its best, was never merely syntax production. It was creation.
A developer writing a function was encoding decisions: why this algorithm and not that one, why this data structure given these access patterns, why this abstraction level given this team’s maintenance capacity.
Every function was a record of judgment.
Every PR was the transmission of that judgment
from one mind to others who would live with it.
What AI has produced instead is assembly. The parts arrive pre-formed, assembled according to statistical patterns learned from millions of human decisions.
The result can look exactly like creation from the outside: correct, clean, well-structured. But the judgment is absent. The accountability is absent.
A PR that carries assembled code is not a contract. It is a delivery.
It is merely a delivery dropped at the door, with no one to account for its contents.
OpenClaw’s maintainer Shadow stated this plainly on Discord:
“If you can’t understand how to run a command line,
this is far too dangerous of a project for you to use safely.”
This was not a technical limitation notice. It was the PR problem made explicit: the gap between what you shipped and what you can explain is exactly the size of your unknown blast radius.
This unease is not isolated to maintainers facing a flood of PRs. Veteran developers evaluating AI for their own work are reaching the exact same conclusion.
Jeff Geerling, one of the most widely followed infrastructure developers in the open source community, put it plainly in February 2026 after using AI to migrate his own blog:
“I admit, it’s really helpful if you know what you’re doing.
But I also spent a lot of time manually testing and reviewing
all the generated code before I ran it in production.
And I’d spend even more time on that process to button it up,
if I ever considered throwing it over the wall
to another project maintainer for review.”
Throwing it over the wall.
That phrase is the PR problem in five words.
The wall is the gate.
What lands on the other side is not a contribution. It is a transfer of risk to someone who did not write it, cannot fully explain it, and will now be responsible for it.
Qodo’s 2025 State of AI Code Quality report quantified exactly what this “transfer of risk” looks like in practice:
25% of developers estimated that 1 in 5 AI-generated suggestions contained factual errors or misleading code.
Only 3.8% reported high confidence in shipping AI-generated code without significant review.
The other 96.2% shipped it anyway, because the velocity of development had made it the path of least resistance.
The PR Gate Checklist - What Understanding Actually Requires
Before any AI-assisted PR merges, the author should be able to answer these questions. If they cannot, the gate should not open.
What does this change do, and why is it structured this way rather than an alternative approach?
Which sections were AI-generated, and which were human-authored?
Does this change affect the security model, data flow, or trust boundaries?
Have edge cases been considered -- not just tested, but reasoned about?
What is the rollback plan if this fails in production?
Are there architectural decisions embedded here that the team has not explicitly discussed?
What does this PR not cover that a future maintainer might assume it does?
Can the reviewer explain this change after the author leaves the room?
These questions are not process overhead. They are the contract. A PR that cannot answer them has not been reviewed. It has been rubber-stamped.
IV. The Loop That Nobody Closed
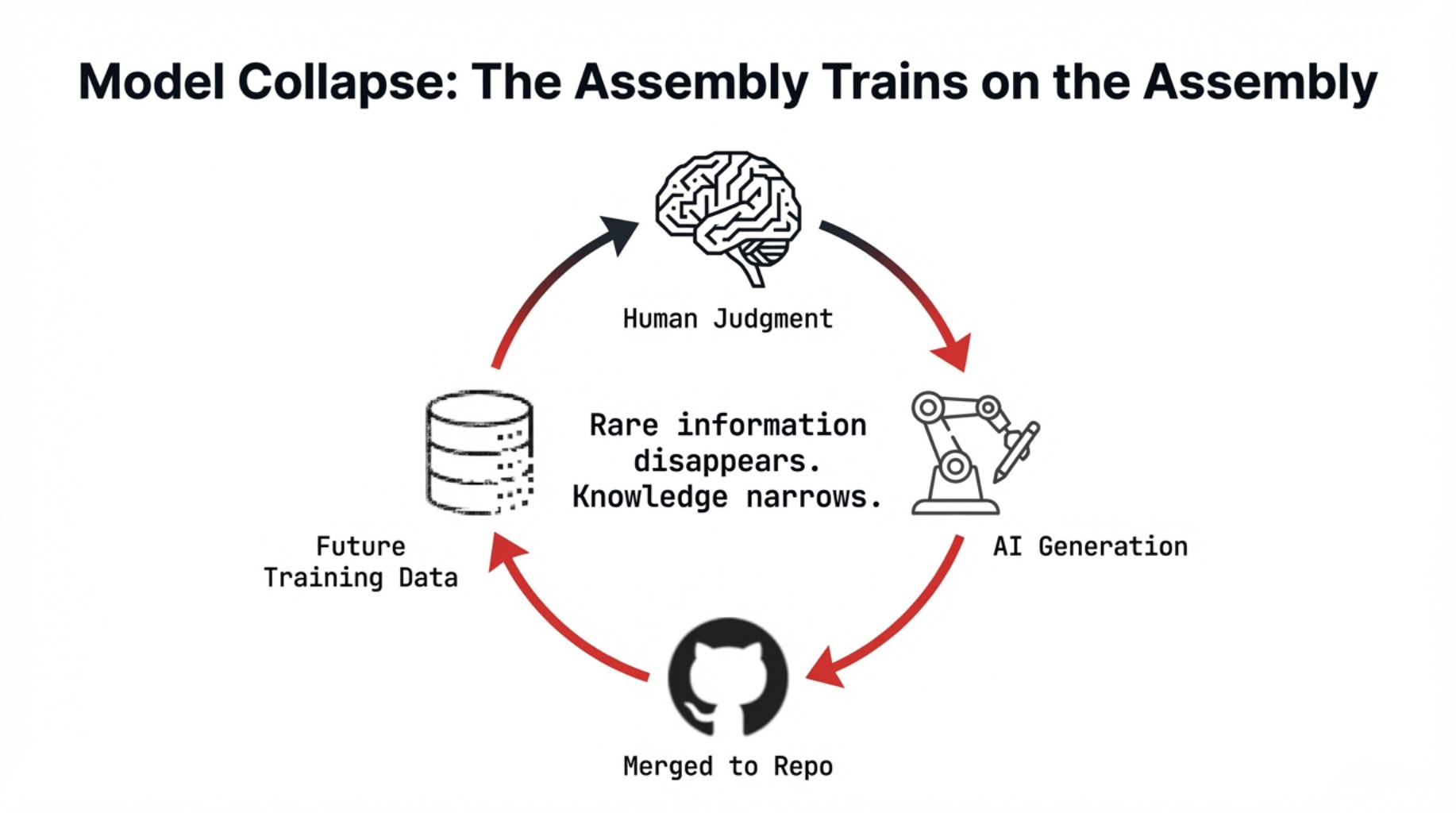
There is a third dimension to this problem, operating on a longer timescale than individual PRs or projects. It concerns what happens to AI itself when AI-generated code becomes a significant share of what future AI trains on.
In July 2024, Ilia Shumailov and colleagues published a study in Nature on “model collapse.” When generative models are trained recursively on outputs produced by earlier models, they degrade across generations.
Rare information disappears first. Outputs become more homogeneous. The model’s effective knowledge narrows until it converges toward a degraded average.
This mechanism compounds through a toxic, inescapable loop:
The Web is saturated: By April 2025, 74.2% of newly created webpages contained AI-generated text, and AI-written content in Google’s top 20 results nearly doubled.
The Data is scraped: This synthetic content is continuously scraped and fed right back into training datasets.
The Errors amplify: With each generation, the learning algorithm loses rare edge cases, shrinks its functional expressivity, and introduces systematic biases. Each generation inherits and amplifies what the previous one distorted.
Applied to code, the implications are grim. As AI-generated PRs flood public repositories, they inevitably enter the datasets used to train the next generation of coding assistants.
The hallucinations compound. The architectural anti-patterns propagate. The narrow range of solutions current AI models favor becomes, recursively, the range of solutions future AI models know.
The assembly trains on the assembly.
The code without creation trains code that cannot create.
And here, OpenClaw becomes something beyond a product story. Its massive repository—its architecture, its patterns, its community-developed workarounds for known vulnerabilities—all of this is now permanently part of the public record that future AI will train on.
What enters the training data is not Steinberger’s reasoning. Not the security decisions made under pressure. Not the architectural trade-offs meant for a personal project that was never intended to become infrastructure.
Just the code. The assembly without the creation.
As the 2026 IEEE Software report on synthetic training data found, the question is no longer whether AI-generated code enters training pipelines—it does—but whether the industry has mechanisms to detect and filter degraded signal before it compounds. Currently, for the most part, it does not.
As PRs merge and training datasets swell, this loop closes entirely unmonitored.
V. The Wall You Cannot See
There is a concept that sits at the center of everything described above, and it requires a precise name: the Wall of Missing Information.
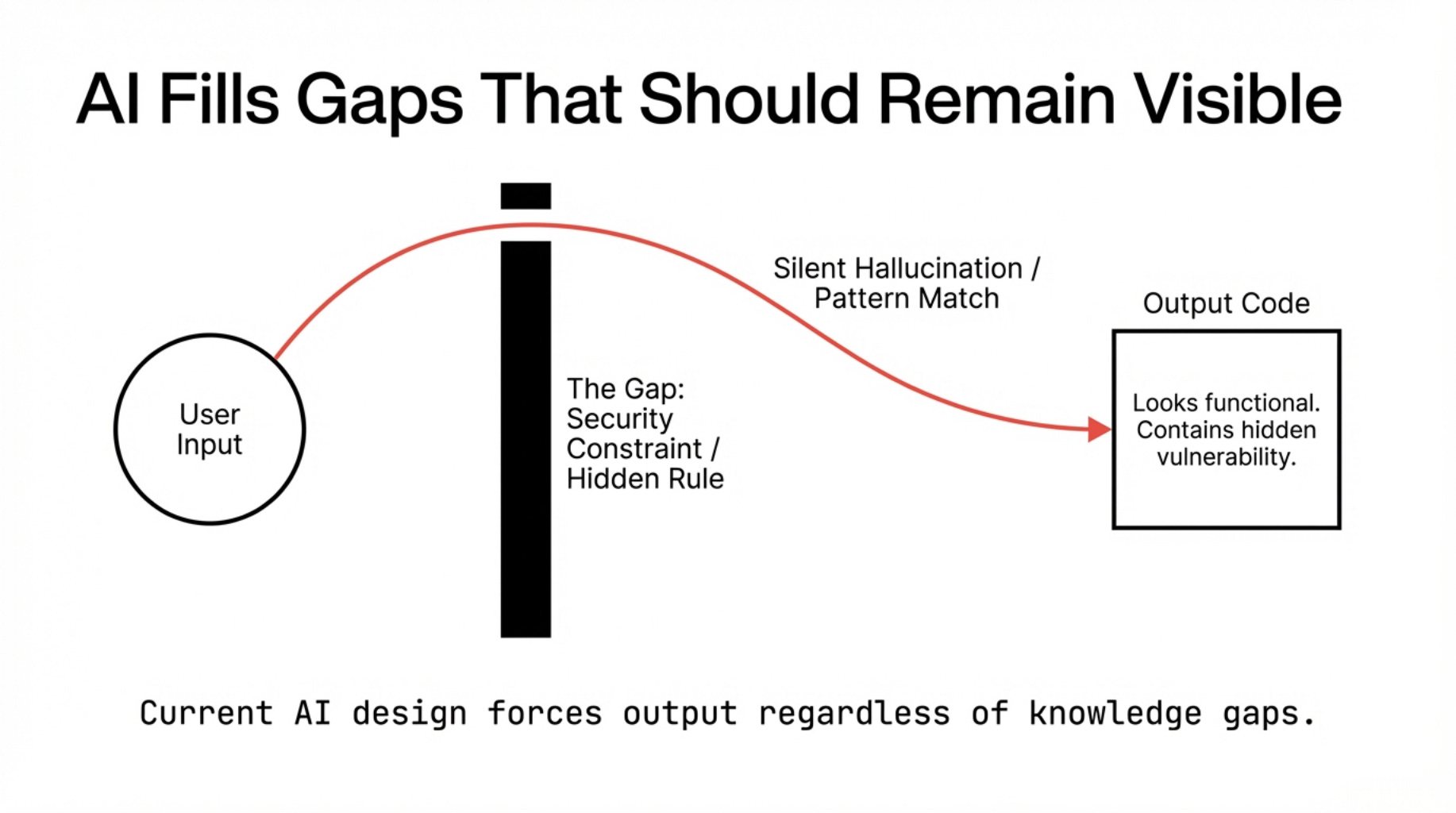
Current AI systems are designed, at the architectural level, to never surface what they do not know. An AI coding assistant will inevitably encounter gaps. An unknown architectural constraint. A security model outside its context window.
A business rule hidden in a 2019 Confluence page. But when it hits these blind spots, it does not stop. It does not flag the void. It fills it.
It generates code that is plausible given what it knows, which is a different thing entirely from being correct given what is true.
This is not a failure mode. It is the design. The incentive structure that produced current AI systems rewarded confident output.
Hesitation was a signal of weakness in user experience. The systems that shipped were the ones that produced answers, not questions.
The result is a specific architectural property: AI fills gaps that should remain visible.
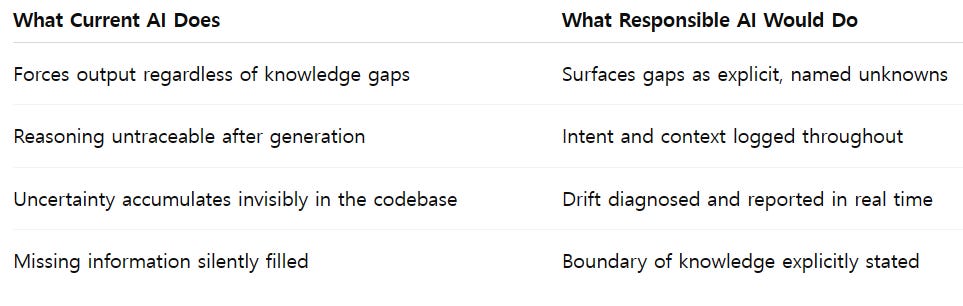
The PR process is exactly the moment when this property becomes dangerous. A PR is a gate. It is the transition from “someone’s idea” to “the team’s shared responsibility.”
If an AI-assisted PR cannot answer “why was this written this way” -- if the author cannot explain it and the AI has no mechanism to explain it -- the gate should not open. The check is not whether the code compiles. The check is whether the reasoning is present.
What O’Reilly’s ClawHub demonstration showed was the full form of this problem. The malicious skill was not obviously wrong. The code was syntactically correct. The documentation was plausible. The ranking looked earned. Every signal the review process could evaluate was manufactured to pass it. The missing information—that the skill was malicious, that the ranking was fabricated—sat on the other side of a Wall the system had no mechanism to see through.
Cisco’s AI research team named the underlying architectural limit without softening it
“The LLM cannot inherently distinguish
between trusted user instructions and untrusted retrieved data.”
Once the merge is approved, that gap becomes permanently embedded. The Wall stands invisible, severing the link between the code that shipped and the humans who must account for it.
VI. The Builder Who Already Knew
On February 14, 2026, Peter Steinberger published the blog post that ended his time as OpenClaw’s creator.
It is a short post. Deliberately optimistic in tone. But one sentence reads differently once you know what the previous ten weeks had looked like:
“My next mission is to build an agent that even my mum can use.
That’ll need a much broader change, a lot more thought on how to do it safely,
and access to the very latest models and research.”
A lot more thought on how to do it safely.
He didn’t say: I have learned how to do it safely and am taking that knowledge to a larger stage.
He said: I need more thought. More resources. More structure. What I built demonstrated the demand; it cannot, by itself, become the answer.
This is a confession embedded in a press release.
Not a failure confession -- OpenClaw succeeded at everything Steinberger originally intended, and then exceeded it by orders of magnitude. It is a confession about what success revealed: a playground project cannot carry the weight of universal infrastructure.
One person cannot review what thousands contribute. One repository cannot enforce the security model that a hundred thousand deployment environments require.
The PR process Steinberger had designed for his own use—local, personal, trusted—had no mechanism for what arrived.
Every day, contributions came in from developers who had never seen the codebase and would never be accountable for the consequences of what they added. Every merged PR carried someone’s intentions and nobody’s full context.
Steinberger was shipping security improvements continuously throughout—VirusTotal integration, mandatory skill scanning, access controls. But speed of repair and speed of exposure were not the same race. The architecture had been built for one, and was now living in the other.
He knew. Builders usually know, at some level, when the thing they made has grown beyond what they can be responsible for. The knowledge sits below the optimism of the blog post, visible in the phrasing: a lot more thought on how to do it safely. Not faster. Not bigger. Safely.
The Pull Request process failed OpenClaw not because it was implemented badly, but because it was applied to something it was never designed to handle: a velocity of contributions, from a scale of contributors, with a diversity of intentions, that exceeded any human’s capacity to evaluate what was arriving. The reasoning simply never caught up
VII. What Governance Actually Means
None of this argues against AI-assisted development. Teams are getting something real from the assistance. The question is not whether to use AI. The question is whether to use it with or without a gate that actually functions as a gate.
The research and the OpenClaw case together point toward what functioning governance requires—not as a list of rules, but as a set of commitments:
Explainability as a precondition for merging: Authors must explain the why behind their AI-assisted code. “The AI wrote it and tests passed” is not a valid review. If the author cannot defend the logic, the gate stays closed.
Design-first, implementation-second: AI implements; humans architect. Because AI lacks system context, all significant design decisions must be agreed upon by humans before a single line of code is generated.
Treating gaps as first-class signals: Explicitly state what you do not know. A PR stating, “I haven’t verified the security impact,” is vastly safer than a silent guess. Teams must name their unknowns.
Maintainer authority over obligation: An unaligned AI PR is not a gift; it is future technical debt. Maintainers must exercise the authority to close unhelpful PRs quickly, explain briefly, and move on without guilt.
Data provenance as infrastructure: Track and tag which parts of your codebase are AI-generated. Tagging your own AI outputs is the first practical defense against feeding degraded code back into future AI training loops.
The underlying principle is simple: Traceability is the minimum requirement for ownership. If you cannot trace the reasoning behind a change, you do not own it; the code owns you.
A codebase built on assembled syntax rather than human intent is a ticking liability. It will surface its hidden debts in production through failures that no one on your team has the context to explain or the power to fix.

Conclusion: What the Gate Is For

The software industry is moving at an impressive, almost predatory speed. The productivity gains are real, and the capabilities AI has granted the individual developer are undeniable. A single builder in Vienna can now reach a hundred thousand users in a fortnight.
But since 2023, the fundamental parts of our craft have been falling off. First, we lost the author’s ability to defend every line of code. Then, we lost the reviewer’s confidence that what passed the gate was actually understood. Now, the feedback loops are cannibalizing themselves—AI is training on AI, and the degradation of our shared knowledge has begun.
Peter Steinberger’s final words as the creator of OpenClaw were not a victory lap; they were a confession:
“What I want is to change the world, not build a large company,
and teaming up with OpenAI is the fastest way to bring this to everyone.”
Read this as an admission of the limit. He proved his idea was world-changing, but he also discovered that the gap between a brilliant prototype and a safe, universal infrastructure is a void that no single human can bridge alone. It required institutional governance and resources that a one-person repository—and a traditional PR process—could no longer sustain.
He described the ultimate reality of the Pull Request: it is the fragile gate between one person’s intent and the world’s shared responsibility.
The PR was designed for a world where merging code meant merging understanding. That world is now under unprecedented pressure from systems that fill gaps without naming them, looking perfect on the surface while remaining hollow within.
In this new reality, the question “Can you explain this code?” is not an obstacle to velocity. It is the gate. It is the entire point of the gate. The answer to that question—not your star count or your deployment speed—is the only thing that distinguishes a codebase you own from a codebase that owns you.
Peter Steinberger learned this by watching his own gate collapse under the weight of the flood. The question for the rest of us is whether we will start asking it before we find out the same way.
The question is whether the rest of us will ask it before we find out the same way.
📚 References & Sources
Technical & Industry Reports
CodeRabbit. “State of AI vs Human Code Generation Report.” December 2025.
Google Cloud / DORA. “State of AI-assisted Software Development 2025.” 2025.
Cortex. “Engineering in the Age of AI: 2026 Benchmark Report.” 2026.
Tidelift. “State of the Open Source Maintainer Report 2024.” 2024.
Academic Research
Shumailov, Ilia et al. “AI Models Collapse When Trained on Recursively Generated Data.” Nature 631, 755–759 (2024).
IEEE Software. “Detecting and Mitigating Synthetic Data Contamination in LLM Training Pipelines.” 2026. Search IEEE Xplore
Security Advisories & Analyses
Belgium Centre for Cybersecurity (CCB). “Warning: Critical Vulnerability in OpenClaw Allows 1-Click Remote Code Execution.” February 2026.
National Vulnerability Database (NVD). CVE-2026-25253: OpenClaw – One-click Remote Code Execution. GitHub Security Advisory (GHSA):
China MIIT. Security Warning on OpenClaw (February 2026).
Community & Official Blog Posts
Steinberger, Peter. “OpenClaw, OpenAI and the Future.” February 14, 2026.
Stenberg, Daniel. “Death by a Thousand Slops.” July 14, 2025.
Stenberg, Daniel. “The End of the curl Bug Bounty.” January 26, 2026.
Wolf, Ashley (GitHub). “Welcome to the Eternal September of Open Source — Here’s What We Plan to Do for Maintainers.” February 12, 2026.
GitHub Changelog. “New Repository Settings for Configuring Pull Request Access.” February 13, 2026. Search GitHub Blog or Community Discussions (#187038)
Qodo (formerly CodiumAI) “State of AI Code Quality 2025”
Cisco AI Threat Research — “Personal AI Agents like OpenClaw Are a Security Nightmare”
Koi Security ClawHub Audit (341 malicious skills) — Referenced in secondary coverage
Jeff Geerling — “AI is Destroying Open Source…”